目次。
この文章を読んで、面白い!役に立った!...と思った分だけ、投げ銭していただけると嬉しいです。
【宣伝】ギターも歌も下手だけど、弾き語りをやっているので、よければ聴いてください。
はじめに。
2022年のノーベル物理学賞は、「量子もつれ光子対を用いた、ベルの不等式の破れの実験的検証。ならびに量子情報科学の開拓」だった。量子情報科学分野のノーベル賞受賞は、初めてのことなので、それに触発されて、何かしら量子情報科学関連の文章を書くことにした。
以前から、量子敵対的生成ネットワークを解説する文章を書きたいと思っていたが、それには、量子コンピュータ上での最急降下法の知識が必要。
ということで、まずは量子コンピュータ上での最急降下法の話をする。量子敵対的生成ネットワークの解説は、時間とやる気があれば、今後するかも。
一般向けではないので、ご容赦ください。量子情報科学の本を読みとおすことができれば、この文章も読めると思います。そして、この本を読めば、2022年のノーベル物理学賞のことがよくわかります。

「高校数学の知識がない人が量子情報科学の論文が読めるようになるために、どういう本を読めばいいか」というのを以下の文章の最後の方に書いたので、よければどうぞ。
量子コンピュータ上での最急降下法の論文も量子敵対生成ネットワークの論文も、以下の文章で紹介しているので、よければ。
==========
ちょくちょく宣伝しているが、新型コロナウイルスの論文を使って、「研究者がどうやって未知のウイルスの正体を暴くのか?」について説明した文章を一般の人向けに書いたので興味のある方はどうぞ。
blog.sun-ek2.com
加えて、PCR検査の仕組みと、それに代わるかもしれないゲノム編集技術を応用した新しい検査方法に関する論文を一般向けに説明したので興味のある方はどうぞ。
blog.sun-ek2.com
さらに、試験管内で新型コロナウイルスのスパイクタンパク質を進化させて、色々な変異体を取ってきたという論文を一般向けに説明したので興味のある方はどうぞ。
==========
読んだ論文。
題名。
Classification with Quantum Neural Networks on Near Term Processors
著者。
Edward Farhi, Hartmut Neven
量子ニューラルネットワーク。
論文で扱っている量子ニューラルネットワークは、こんな感じ。
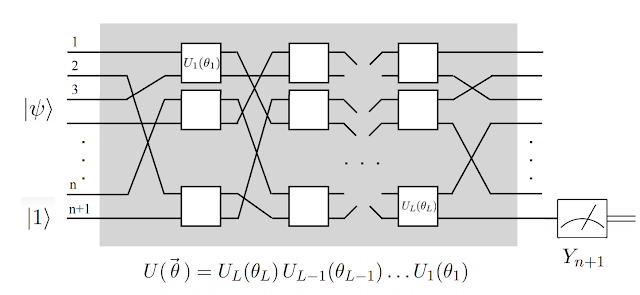
https://ai.googleblog.com/2018/12/exploring-quantum-neural-networks.htmlから引用。
L個の2量子ビットゲートに(z+1)量子ビットを入力する。z個の量子ビットは、入力データで、最後の1量子ビットは、最終出力を得るための量子ビット。
量子ビット列の最後をYゲートに通して、測定すると、次のような期待値が得られる。
この期待値は、-1から1までの値のどれかを取る。これを教師データのラベルに一致させるように学習を行う。
ユニタリ変換を積み重ねるだけでは、厳密には、ニューラルネットワークとは言えない。
…ということも、一応、言及しておこうと思う。
厳密には、この量子ニューラルネットワークは、ニューラルネットワークではない。線形変換であるユニタリ変換を一億個、一兆個、一京個、積み重ねても、それは、ただ一つのユニタリ変換で表現されてしまう。ユニタリ変換でできたネットワークの層が一億層、一兆層、一京層、あったとしても、それは、一層と変わりがない。
これは、通常のニューラルネットワーク(ディープラーニング)でも同じこと。それぞれの層の出力は、非線形関数(シグモイド関数、ReLUなど)を通って出てくると思う。もし、ニューラルネットワークに線形関数しか使われてなければ、層をいくら重ねても、線形関数の性質より、全て一層に置き換えられる。
この問題は、量子ニューロンという技術で一応、解決することができる。以下のwebサイトの説明がわかりやすかったので、よければ。
ということも、一応、念頭に置いて、今後の文章を読んでください。
誤差関数(目的関数)。
誤差関数は、次の通り。
は、教師データのラベル。誤差関数は、出力の期待値と教師データのラベルが一致すれば、0になり、一致しなければ、1となる。
パウリ行列のテンソル積を
とおくと、
は、次のように書くことができる。
ユニタリ行列がエルミート行列の行列指数関数になる理由は、以下のwebサイトを参照のこと。
任意のエルミート行列がパウリ行列で展開できる理由は、以下のwebサイトを参照のこと。
electrodynamics.hatenablog.com
であることを念頭に、
を
で偏微分すると、
複素関数の内積の公式を使うと、
*論文の式(23)は、がないが、僕はつけた方がいいと思う。
は、虚部(a+ibのbの部分)を表す。複素共役の引き算なので、実部が消え、純虚数となる。そこにiがかかるので、最終的な答えは実数になる。
演算子が長ったらしいので、以下のように書き換える。
を
で偏微分すると、
誤差関数の偏微分を量子回路で求める。
補助量子ビットを用意し、アダマール変換を行う。
補助量子ビットを制御量子ビットとし、制御ユニタリ変換を行う。
補助量子ビットにさらにアダマール変換を行う。
*論文の式(28)と違うが、流石にこれは僕の方が正しいと思う。
を次のようにおく。
補助量子ビットを測定し、0がでる確率は、
よって、
最急降下法。
ここまで求めることができれば、あとは普通のニューラルネットワーク(ディープラーニング)の最急降下法と変わらない。
とおくと、
一旦、ではなく、
と書いたのは、これが
に沿った
の方向微分であることを強調するため。
誤差関数の最小値は0なので、
これより小さな値でパラメータ更新をすると、いつまでたっても、誤差関数が収束しない。学習率をとすると、
さいごに。
間違いはあれば、ご連絡頂けると幸いです。
この文章を読んで、面白い!役に立った!...と思った分だけ、投げ銭していただけると嬉しいです。